How to use LLMs effectively
Dawson Metzger-Fleetwood
|
8 min read
Large language models have exploded in popularity. Over the past year and a half, the capabilities and use cases for large language models have become strategic imperatives for organizations of all types. With such powerful models at your disposal, it’s no surprise that integrating one into your workflow has been shown to lead to substantial increases in productivity. A working study at Harvard Business School found that individuals who used GPT-4 performed with increased the quality and speed of a wide variety of tasks.
In order to get the most out of this tool, you first have to understand how to use it effectively. This article explores some of the most effective, researched backed ways to do just that. Let’s dive in.
Step 1: Plan Ahead
English teachers everywhere will tell you that the best way (for humans) to write a good paper is to begin with an outline. The same holds true for LLMs! Research has shown that asking an LLM to “think” through an answer beforehand increases performance. Specifically, asking the LLM to spend a few sentences explaining background context, assumptions, and step-by-step thinking before trying to answer a question increases the quality of the answer provided.
Initially this surprised me, but in hindsight, context is everything. The reason is this: LLMs spend a fixed amount of computation for every token they generate, regardless of the difficulty of the question being answered. Also, LLMs are ‘autoregressive’, meaning that one forward pass of the model produces one token, and that token is fed back into the model as part of the input when generating the next token. Asking the model to “think through” an answer beforehand increases the total amount of computation spent on the answer. The earlier part of the model’s response serves as highly relevant context when constructing the answer itself.
Step 2: Use a Custom Instruction
Jeremy Howard, a data scientist, AI researcher, and former President and Chief Scientist of Kaggle has a great prompt that accomplishes this well. I use this prompt in my custom instructions for ChatGPT and have observed an increase in the quality of the answers I receive.
The custom instruction
“You are an autoregressive language model that has been fine-tuned with instruction-tuning and RLHF. You carefully provide accurate, factual, thoughtful, nuanced answers, and are brilliant at reasoning. If you think there might not be a correct answer, you say so.
Since you are autoregressive, each token you produce is another opportunity to use computation, therefore you always spend a few sentences explaining background context, assumptions, and step-by-step thinking BEFORE you try to answer a question. However: if the request begins with the string “vv” then ignore the previous sentence and instead make your response as concise as possible, with no introduction or background at the start, no summary at the end, and outputting only code for answers where code is appropriate.
Your users are experts in Al and ethics, so they already know you’re a language model and your capabilities and limitations, so don’t remind them of that.
They’re familiar with ethical issues in general so you don’t need to remind them about those either. Don’t be verbose in your answers, but do provide details and examples where it might help the explanation.”
A Hacker’s Guide to Language Models
Step 3: Reflect
Similarly, asking the LLM to critique its answer after providing it can uncover mistakes, and even completely overcome hallucinations. I’ve found that GPT-4 can correctly diagnose its own errors extremely well. In the HumanEval benchmark, which tests Python coding ability, GPT-4 scored 67%. With reflection, it scored over 90%. You can view the study here.
A brief look into the world of agents
Planning ahead and reflecting are so powerful at increasing performance that entire workflows have been built around augmenting LLMs with these capabilities. By creating a “feedback loop” system where the LLM can repeatedly prompt itself, evaluate its response, and in some cases include feedback from an external environment, significant performance improvements can be achieved.
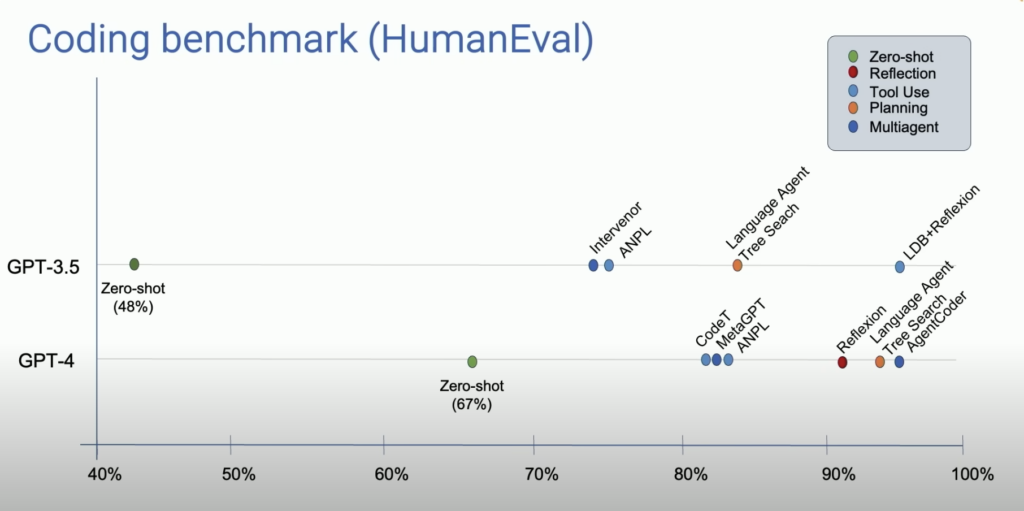
This image illustrates how, given the feedback loop system, GPT-3.5 can outperform vanilla GPT-4 – sometimes by a wide margin. When these feedback loops become complex enough, you end up with what is called an “agent.” More on this topic is beyond the scope of this article, but I encourage you to explore the fascinating world of LLM agents. If you’re unsure where to start, check out the Voyager paper.
Step 4: Keep the Context Relevant
Language models today can take long contexts as input, with GPT-4 capable of taking a whopping 128,000 tokens — about 96,000 words or 192 pages — at one time. Claude 2 is capable of taking 200,000 tokens at once. Recently, Google released Gemini-1.5, a model that has a 10 million token context window. However, a growing body of research suggests that LLMs do not make use of long contexts like this effectively. “Performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts.” The term for this phenomenon is “lost in the middle.”
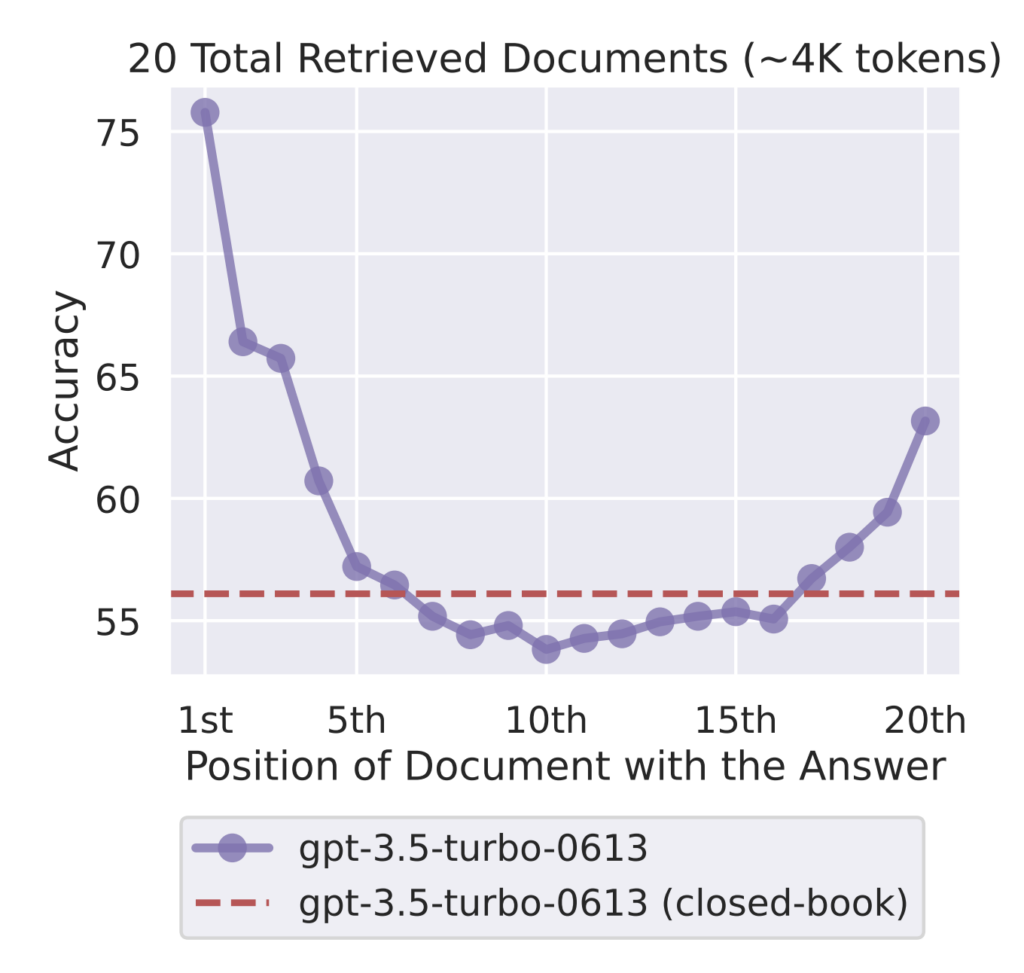
What this means for us is that we ought to prevent our conversations with LLMs from getting too long. I’ve noticed that pasting unnecessarily large blocks of text repeatedly and asking for slight edits is a poor use of the model, and will quickly result in the model becoming incoherent — forgetting earlier parts of the conversation, ignoring your instructions, and providing generally erratic and unhelpful responses. Taking the time to curate short, useful context for your prompts, and asking the model for short responses, pays off with longer conversations and more prompt iteration before the model starts to behave incoherently.
This ‘lost in the middle’ effect was only present when the models processed sequences longer than those they were trained on. This indicates that the ‘lost in the middle’ effect is a result of how transformers generalize to sequences longer than their training data, and not an indication of a limitation on the sequence length that transformers can handle. Furthermore, recent work by Google DeepMind has shown that this ‘lost in the middle’ effect can be mitigated. The new Gemini 1.5 Pro model has a higher recall accuracy at 10 million tokens than Anthropic’s Claude 2 (a previous leader in long context performance) has at 200k tokens.
Step 5: Help it Understand the Goal: Few-Shot Learning
LLMs can generalize well to types of text generation tasks they were never trained on. By providing a description of how to perform the task, GPT-4 can almost always perform it successfully. The term for this is “in-context learning.” Rather than being trained to perform the task by updating model weights via training on input-output pairs, that specific task is learned via the prompt used as the input of the LLM. There are a few important sub-categories of in-context learning :
LLMs can generalize well to types of text generation tasks they were never trained on. By providing a description of how to perform the task, GPT-4 can almost always perform it successfully. The term for this is “in-context learning.” Rather than being trained to perform the task by updating model weights via training on input-output pairs, that specific task is learned via the prompt used as the input of the LLM. There are a few important sub-categories of in-context learning:
- Zero-shot learning — if only an instruction is given, this is known as zero-shot learning. The model must perform the task without any explicit examples of how to perform the task successfully.
- One-shot learning — A single example is provided for how to perform the task successfully. This one example is an input-output pair passed in as part of the prompt.
- Few-shot learning — A few examples are provided for how to perform the task successfully.
When using a model like GPT-4, most people just tell it what they want, and hope for the best. In other words, they use zero-shot learning. However, research shows that providing one example is better than no examples, and a few examples are better than one. Across the board, LLMs score higher on benchmarks when prompting strategies use more examples. This means that whenever possible, provide the model not just with a descriptive instruction, but also a few examples of exactly what you want. You can read more here.
Step 6: Tool Selection. Understand what LLMs aren’t good at (and why)
LLMs are great at writing regexes. They’re awesome at writing boilerplate code. They’re good for discovering libraries and packages you didn’t know about, and are often very useful for quickly learning the syntax of these libraries. LLMs know git, unix commands, and so much more. But they are terrible at some things too.
Hallucinations
Hallucination (Artificial Intelligence): n. A tendency to invent facts in moments of uncertainty.
LLM training follows two basic steps. The first step is to train a next token predictor on as much text as possible. Given a sequence of text as input, the LLM is trained to predict the text that will come next. This instills “understanding” into the LLM, and no humans are needed to curate a dataset. Use as much raw, unstructured text from the internet as you can. After a few weeks and a few million dollars, you have a “compressed” version of the internet.
The second step is to fine tune the model. Keep the model as a next token predictor, but now instead of raw text taken straight from the internet, the data used is a set of handcrafted conversations created by humans.
This second step is what produces a model that can converse — that can follow instructions, understand iterative feedback, and communicate effectively with a human being. However there is a downside. Occasionally the training data will contain a question the model doesn’t know the answer to, but the human labeler did. Ideally, in this case the model would say something like “I’m sorry I can’t help, I don’t know the answer.” But instead it has been trained to produce the output the human did. From the perspective of the model, it is being trained to make up an answer if it doesn’t know the correct one. In other words, the output of the model is not conditioned on the knowledge of the model, but rather on the knowledge of the human who created the fine tuning dataset.
This leads to a phenomenon known as “hallucination,” a condition where, when confronted with a question the model doesn’t know how to answer, the model will produce a plausible sounding — but totally false — answer instead.
This is already becoming a problem. Recently, lawyers were sanctioned after it was revealed that they used ChatGPT to generate legal briefs. They were discovered because the model completely hallucinated multiple case citations.
It’s just what you wanted to hear
If I ask GPT-4 to compare two options, but express a slight preference for one in my prompt, I have found that GPT-4 will often provide justification for that option being the better one. To counteract this, make sure you don’t express a preference in your prompt, or ask explicitly for a list of pros and cons for each option and make the comparison yourself.
Prompt Sensitivity
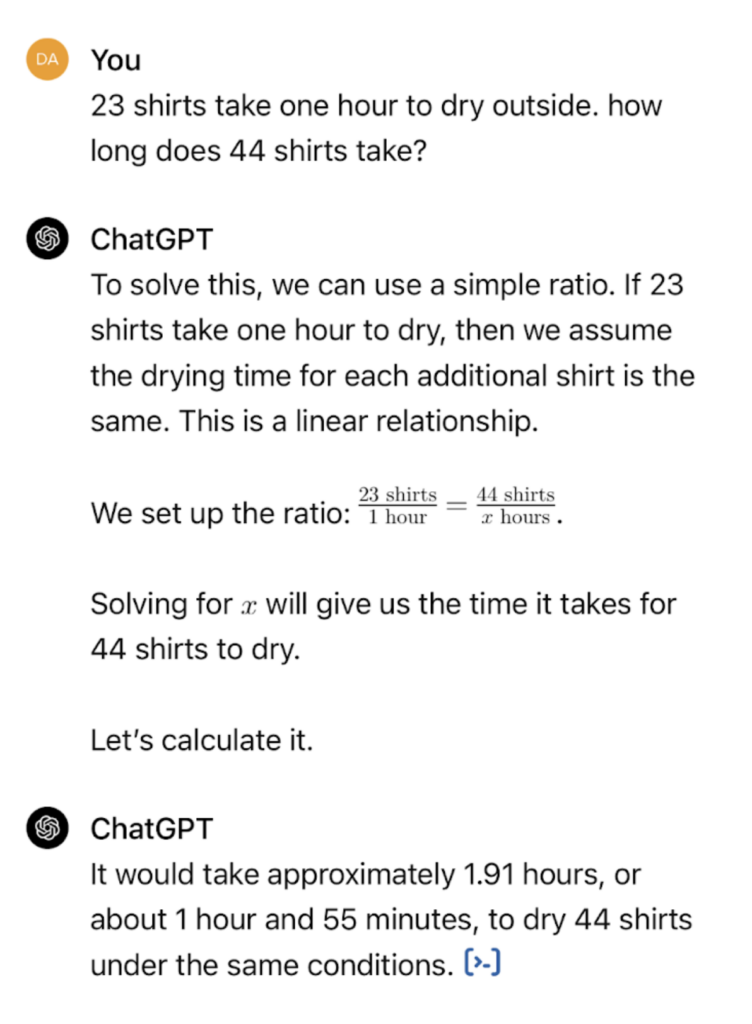
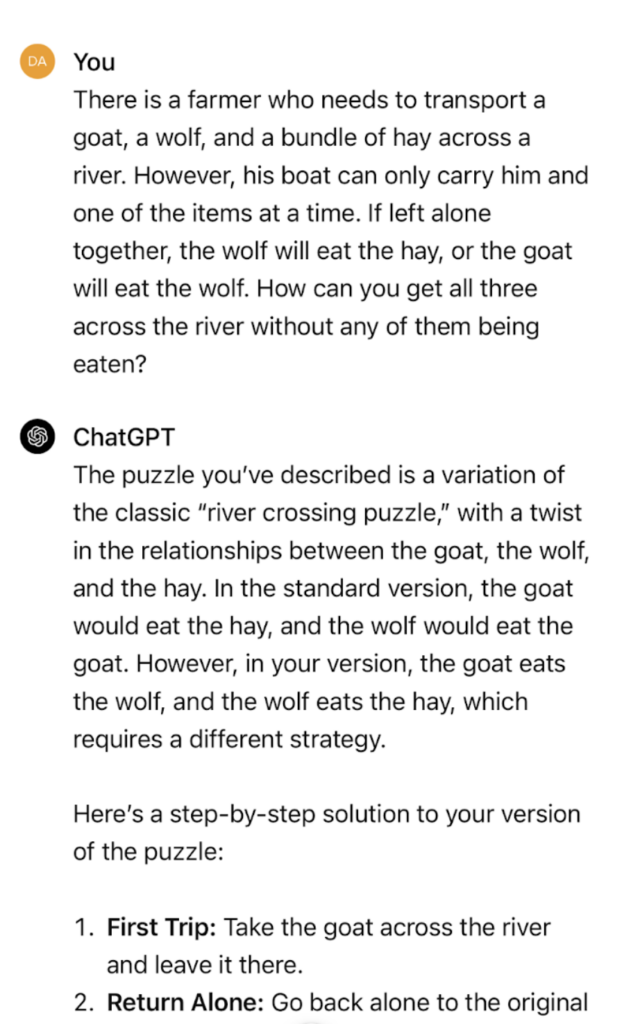
Research has shown that how you ask the model for information can determine whether it supplies the information or not. Even something as simple as prompt formatting can have a huge effect on accuracy.
Consider these two logic puzzles. Notice how seemingly irrelevant changes to the prompt can have a huge impact on accuracy:
Failure
Success

Failure
Success
If a question is proving too difficult for the LLM to answer, don’t be afraid to start a new conversation thread, and try again with different wording and formatting.
Finally…
LLMs are useful tools that can make us much more productive. But they aren’t good enough to do everything (yet). A study by Cornell found that even the best LLMs are still a long way from being able to solve real world software engineering issues. Resolving these issues typically requires coordinating edits across multiple long files, and performing reasoning far more complex than required for traditional code generation. Even with document search and retrieval, these models could only solve 1.7-4.8% of the real world issues they were tested on. And though I tried, GPT-4 could not come close to writing a version of this article that I liked.


